Amazon Web Services Feed
Boosting the Assembly and Deployment of Artificial Intelligence Solutions with KNIME Visual Data Science Tools

By Binoy Das, Partner Solutions Architect at AWS
By Jim Falgout, VP of Operations at KNIME
 |
 |
With rapid advancements in machine learning (ML) techniques over the past decade, intelligent decision-making and prediction systems are poised to transform productivity and lead to significant economic gains.
A study conducted by PwC Global concludes that by the end of this decade, the total positive impact of artificial intelligence (AI) on the global economy could be above $15 trillion, driven mostly by enhancements in consumer products.
To make that happen, however, businesses must make strategic investments in the type of technology that moves AI projects into production (productionizing) and helps customers deploy them. Unfortunately, PwC’s survey reveals the percentage of executives planning to deploy AI has gone down from 20 percent a year ago to only 4 percent at the beginning of 2020.
The primary reason for this decrease is the gap between the growing volume of data and data-driven modeling capabilities, and the necessary skills and toolsets. These are tools to automate rapid development and the monitoring and maintenance of intelligent systems. In other words, there’s a need for robust tools and processes that can productionize AI at scale.
KNIME is an AWS Partner Network (APN) Advanced Technology Partner that provides visual data science tools to help data science teams rapidly build and deploy data-driven solutions that integrate with Amazon Web Services (AWS) decision support tools and services.
In this post, we summarize the barriers to adoption of AI and the ways in which the KNIME tools remove those barriers.
Barriers to Adoption
The lack of in-house data science and machine learning expertise in many organizations makes it difficult to reap the benefits of their investment. Even though these organizations see the huge opportunity available to them in applying ML to solve enterprise challenges, they struggle to get started and act in time.
On the other hand, some organizations may have a strong data science team, but fall short when it comes to integrating their ML models with high volume, high velocity, data sources. It’s difficult for them to deploy the models and retrain them on a continuous basis as data drifts.
AWS provides high-level AI capabilities and services that a business can integrate with their applications. That helps close this gap substantially.
However, organizations without the technical expertise can find it challenging to integrate these capabilities and services with their end product. Designing and building product features based on off-the-shelf AI capabilities is also a challenge.
Visual Data Science Platforms to the Rescue
During the past year, solution providers such as KNIME have stepped into this gap by providing integration platforms with a unified visual front end. These platforms ease the pain of productionizing data-driven intelligent solutions.
Visual data science platforms excel at low code/no code toolsets that enable data collection and transformation, data exploration and visualization, solution deployment and management, and continuous monitoring and optimization.
For example, a retailer with a global presence could use the KNIME analytics platform to quickly integrate with AWS AI services such as Amazon Translate. That integration would enable them to translate document and websites to address consumers and suppliers.
The retailer could also use the KNIME integration to take advantage of the advanced language comprehension capability of Amazon Comprehend to enhance back-office processing.
KNIME also makes it easy for the retailer to connect securely to a data lake in Amazon Simple Storage Service (Amazon S3), where they may have stored the behavioral data of their customers. This lets them easily create a workflow that uses KNIME integration to pass this behavioral data to Amazon Personalize, which generates personalized recommendations to enhance their customer’s experience.
This trend is similar in principal to the trend we noticed a decade ago, in the way that enterprises used a service bus to integrate several of their enterprise applications. Building on to the same design philosophy, visual data science platforms strive to provide end-to-end data workflows and prediction pipelines to large enterprises with distributed digital assets.
Visual Data Science with KNIME
KNIME on AWS provides a visual low/no-code environment allowing customers of all skill levels to create, deploy, and scale AI/ML solutions. These solutions can, in turn, leverage AWS machine learning, storage, and compute resources, along with other in-house technologies.
With KNIME on AWS, teams with heterogeneous skills and varied skill levels can participate in AI/ML projects to drive value across the full end-to-end lifecycle, and do so at scale. KNIME on AWS enables AI/ML solutions to be productionized quickly on top of native, scalable AWS services, and helps speed time to market.
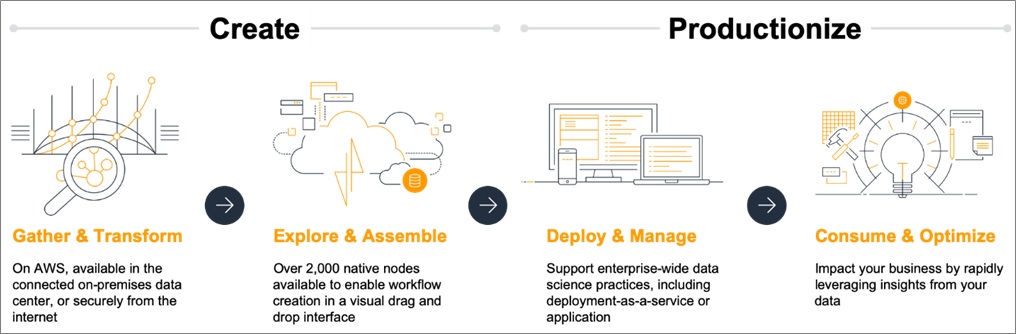
Figure 1 – KNIME on AWS speeds time to market.
The KNIME solution is built around two major product offerings:
- KNIME Analytics Platform is focused on data science.
- KNIME Server is focused on production, deployment, and management.
KNIME Analytics Platform
The KNIME Analytics Platform simplifies data engineering and data science tasks such as data wrangling and preparation, modeling, and visualization. It relies on a visual integrated development environment (IDE) to ease the tasks of data access and exploration, data preparation, and model training and evaluation.
The KNIME Analytics Platform makes it possible for you to blend ML services with custom data science. You can use it create Auto ML and human-in-the-loop workflows across a broad set of enterprise use cases in many industries.
The KNIME Community
The KNIME Analytics Platform is an open source Java-based software, built around the familiar Eclipse IDE.
The visual workflow building tools in the KNIME IDE are useful to novice and expert users alike. Novice users can start putting existing components to use with a few clicks. Expert users can, with little coding, build or modify advanced components, starting with the visual components offered through the platform.
KNIME makes a great case for openness by providing its analytics platform to the community, with the goal of enhancing data-driven innovation. Aside from the analytics platform itself, a wealth of integration nodes, processing components, visual workflows, and other framework extensions are widely available. Many of these extensions are built by the KNIME community.
A dynamic community, where developers can freely share the components and connectors the built using KNIME, saves time and increases the productivity of data science teams. It promotes design best practices through the reuse of components and expert collaboration across the community.
Components of the KNIME Analytics Platform
The KNIME Analytics Platform provides components for common tasks such as:
- File and Database I/O.
- Data filtering and transformation.
- Data visualization using charts and graphs.
- Data mining and Statistical Analysis.
- Time series data processing.
All of these tasks are essential in aggregating and preparing data to build a prediction model. To help build a predictive model, the KNIME Analytics Platform provides visual components for common learners and classifiers.
These include linear and logistic regression, decision tree, K-NN classifier, support vector machine, multilayer perceptron, and those for model evaluation and scoring. Figure 2 shows an example of a workflow of model training for a simple classifier.
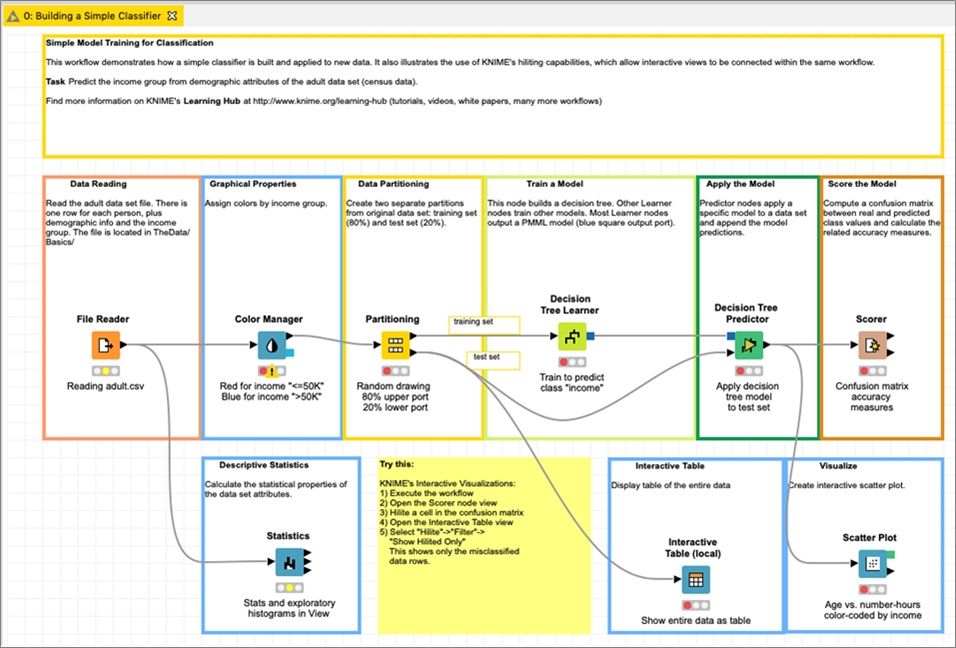
Figure 2 – Example of KNIME model training for a simple classifier.
KNIME Analytics Platform Components for AWS Services
Many KNIME users choose to stage their data on databases and data lakes on AWS. Some, instead, prefer run their enterprise and AI workloads on AWS. Some do both. To support these customers, the KNIME Analytics Platform natively integrates with several AWS services.
For instance, the KNIME database extension connects to Amazon Relational Database Service (Amazon RDS) databases and allows graphical query construction. Similarly, the KNIME S3 connector makes it possible to access and query from flat files stored in Amazon S3 buckets.
Organizing complex SQL queries becomes easier with KNIME’s visual programming paradigm. When you combine it with data wrangling and visualization components, data scientists can more easily prepare data pipelines that feed into ML model training pipelines.
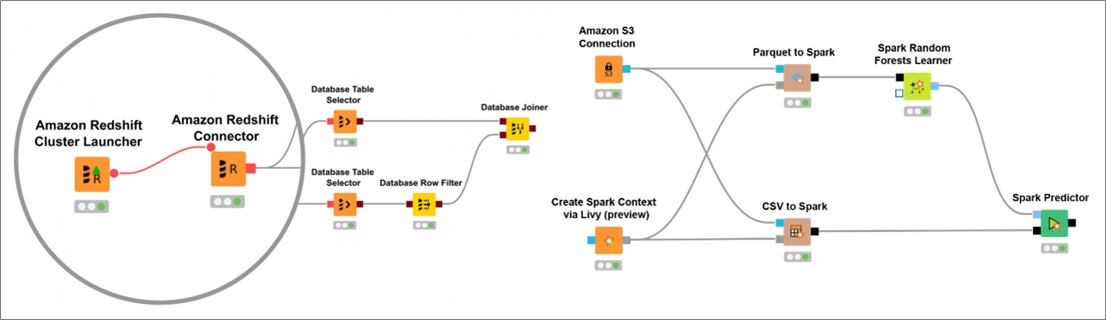
Figure 3 – Data pipelines feeding into ML model training pipelines.
KNIME big data connectors provide easy access to Hadoop/HDFS and SQL query processing, directly in Hive nodes. Using KNIME’s Hive loader makes it easy to import data into a database-like object, enabling relational querying against big data processing engines.
As mentioned earlier, the KNIME Analytics Platform offers direct integration with high-level AI such as Amazon Comprehend, Amazon Personalize, and Amazon Translate. These managed services make modeling and prediction easier for data science practitioners by removing the need to procure, set up, and manage infrastructure.
Using the same visual developer-friendly features, KNIME AWS nodes make integration with AWS APIs for these high-level AI services accessible to developers of all skill levels.
For example, after setting up an AWS authentication node, a developer can set up a workflow to translate a text file using Amazon Translate with just a few clicks. The developer can then set up advanced text processing workflow using an Amazon Comprehend node.

Figure 4 – Amazon Comprehend and Amazon Translate integrated with KNIME AWS Nodes.
Some AWS services require training data to be continuously fed into them. In the case of Amazon Personalize, the training data is needed by the recommendation engine model so it can provide useful personalized product recommendation to users.
With KNIME Amazon Personalize connector, along with KNIME connectors for Amazon S3 or Amazon Redshift for example, data engineers can build such a workflow with little to no exposure to native AWS APIs. This approach allows these AWS services to be more broadly adopted by reducing their barriers to entry.
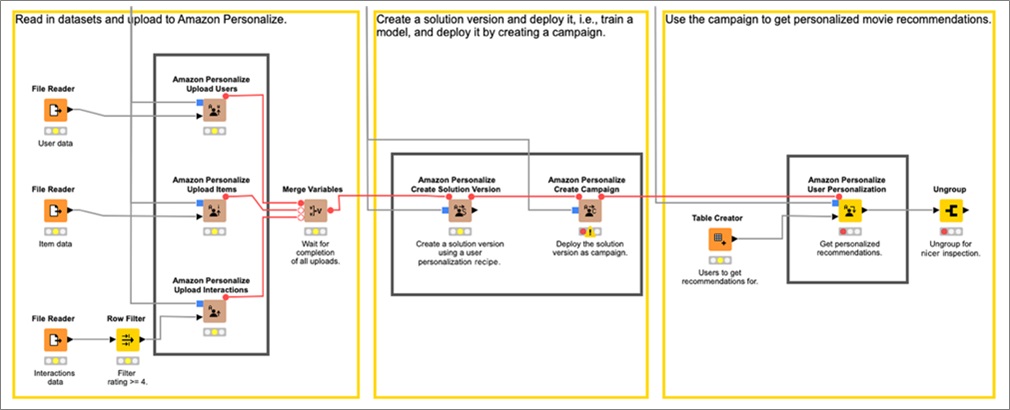
Figure 5 – KNIME connectors feeding training data to Amazon Personalize.
KNIME Hub is a repository of thousands of ready-to-use-blueprints and functional nodes. At present, KNIME doesn’t provide native integration to every AWS service. However, community-developed connectors for specific AWS services are available in the KNIME Hub. They make integration easy, even when a native KNIME connection is not available.
You can also use code snippets that rely on AWS SDK for Python (Boto3) to connect to an AWS service such as Amazon Rekognition or Amazon Textract. Also available are code snippets for custom integration to, for example, Amazon Rekognition. They allow you to detect labels from within images stored in Amazon S3.

Figure 6 – Other means of integrating to AWS services.
To serve predictions, you can deploy KNIME through a RESTful API, either by using the KNIME Dashboard or integrating it with a downstream application.
KNIME Server
While the KNIME Analytics Platform increases the productivity of individuals or teams of data scientists and data engineers, KNIME Server allows enterprises to productionize data science applications. It helps enterprises deploy their applications as RESTful service endpoints, visualizations, or guided analytics applications.
KNIME Server also provides scheduling and distributed execution capabilities. These include features such as team-based collaboration, automation management, and deployment of data science workflows as analytical applications and services.
With KNIME Server, enterprises can control data access and workflows, making it easy to comply with data protection policies. They can also create editable and traceable workflows that can be jointly worked on and reused across teams, helping the teams break through data silos.
You can deploy the KNIME Server on premises, on AWS, or any other cloud platform. Regardless of where you host it, KNIME server runs the KNIME Analytics Platform and all necessary extension, integrations, and workflows using connectors, as needed.

Figure 7 – KNIME Server capabilities and components.
Hosting the KNIME Server on AWS is simple because AWS prices its machine images on either an hourly basis or with a bring-your-own license (BYOL) model.
If you stage large datasets on AWS databases and Amazon S3 buckets, you can substantially reduce your data transfer costs and latency. Deploy the KNIME Server on an Amazon Elastic Compute Cloud (Amazon EC2) instance within your virtual private cloud (VPC).
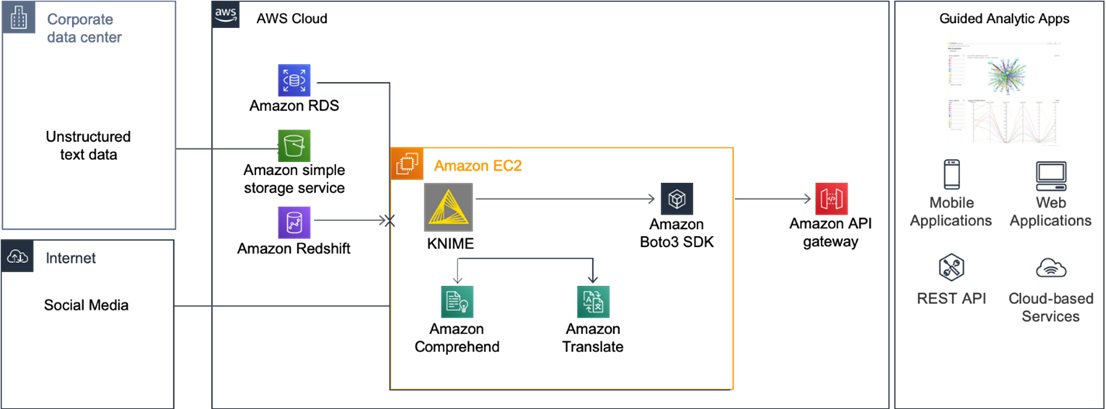
Figure 8 – Reducing transfer costs and latency by deploying KNIME Server on AWS.
This approach also allows for tighter integration via the Amazon API Gateway, allowing data engineering teams to easily provide data science as service features to their users and downstream applications.
Conclusion
As the industry strives to realize the promised value add from the wealth of data they collect through daily business operations, speed of implementation is key. So is the availability of standardized applications/features at higher levels of abstraction.
The KNIME visual integration platform, combined with readily available AI features and widely used algorithms on AWS, speeds up the implementation of many use cases.
Having a large community also serves to promote reuse of features at higher levels of abstraction. For example, the open source KNIME Hub makes available commonly used workflows for customer intelligence, social media, pharmacy/healthcare, retail, finance, government, and manufacturing.
As a result, a data science team looking to do churn prediction for a retail business, sentiment analysis for social media, risk scoring in finance, predictive maintenance in manufacturing, or document processing in government and legal, can find higher-level workflows. They can easily connect those workflows to backend data sources and algorithms that they can readily deploy as a service.
To get started quickly, head to AWS Marketplace and procure Amazon Machine Images (AMIs) for KNIME Server and KNIME Analytics Platform.
.
.
KNIME – APN Partner Spotlight
KNIME is an APN Advanced Technology Partner. KNIME builds software for fast, easy, and intuitive access to advanced data science, helping organizations drive innovation.
Contact KNIME | Solution Overview | AWS Marketplace
*Already worked with KNIME? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.