Amazon Web Services Feed
Creating low-latency, high-volume APIs with Provisioned Concurrency

The AWS Lambda service runs customer code on-demand in response to events. It works by creating a new execution environment and downloading your code. This initial setup is commonly called a “cold start” and introduces latency to the total execution time of the function.
Cold starts happen when you first invoke a function, or when a function is invoked after being inactive for an extended period. They also happen when Lambda scales up a function, since each new instance of the function is a new execution environment.
The serverless community has previously created “function warmer” libraries to help improve the likelihood of a Lambda invocation using an existing execution environment. This is a good approach for development and test workloads, or where you do not need hyper-ready performance. The Provisioned Concurrency feature is designed for workloads needing predictable low-latency.
This blog post shows how to eliminate cold starts in architectures supporting web applications. I reference code from the Ask Around Me example application. This allows users to ask and answer questions in their local geographic area in real time. To learn more, refer to part 1 of the blog application series.
Cold starts and web applications
The Ask Around Me application uses the following backend architecture:

This represents a typical web application. Some Lambda functions are invoked by Amazon API Gateway while others are invoked by services further down the application stack. API Gateway invokes Lambda functions synchronously, meaning the caller is blocked until the function returns a value.
Functions invoked by services like Amazon SQS and Amazon DynamoDB are called asynchronously. This means that the caller continues with other work during execution and the function does not return a value. This application uses both types of invocation:

Generally, cold starts are less impactful in asynchronous executions. The latency overhead in starting the execution environment usually has less impact on overall performance of the application in this case. For web applications in particular, cold starts are most noticeable in synchronous applications closer to the frontend. This is where the speed of the API request has the most influence on the user experience of your application.
In Ask Around Me, there are four Lambda functions supporting the API endpoints for the application. Three of these are lightweight functions that put messages in SQS queues and retrieve data from a DynamoDB table. The most complex function is GetQuestions, which fetches questions based upon the latitude and longitude of the user. This is also expected to receive the most usage, with an expected 50,000 queries per hour, so it’s the most important for performance optimization.
Measuring the existing Lambda function performance
In a previous blog post on load testing this application, the GetQuestions API shows considerable variability in performance. In an API load test for 30 seconds with 20 requests per second, the median response is 175 ms while the slowest is 2149 ms:

In this application, the frontend application waits until this synchronous API call is completed. The median performance is likely acceptable to a user, whereas any response time over one second makes interaction with the application appear slow.
To gain more insight into the performance of this function, I turn on AWS X-Ray for this function. From the Lambda console, I select the GetQuestions function and check the Active tracing check box in the AWS X-Ray panel. After saving the function, X-Ray is now enabled.

I re-run the load test for this function and navigate to the X-Ray console. In the Analytics menu, the Response time distribution panel graphs the performance of the function invocations:

I select all the invocations in the graph after the p95 marker, representing the slowest 5% of all requests. This filters 34 slow requests, which correspond to the number of Concurrent Executions for the function shown in the function’s Metrics console:

X-Ray lists the individual traces for the 34 slowest calls, and selecting the slowest single invocation breaks down the durations of each segment:
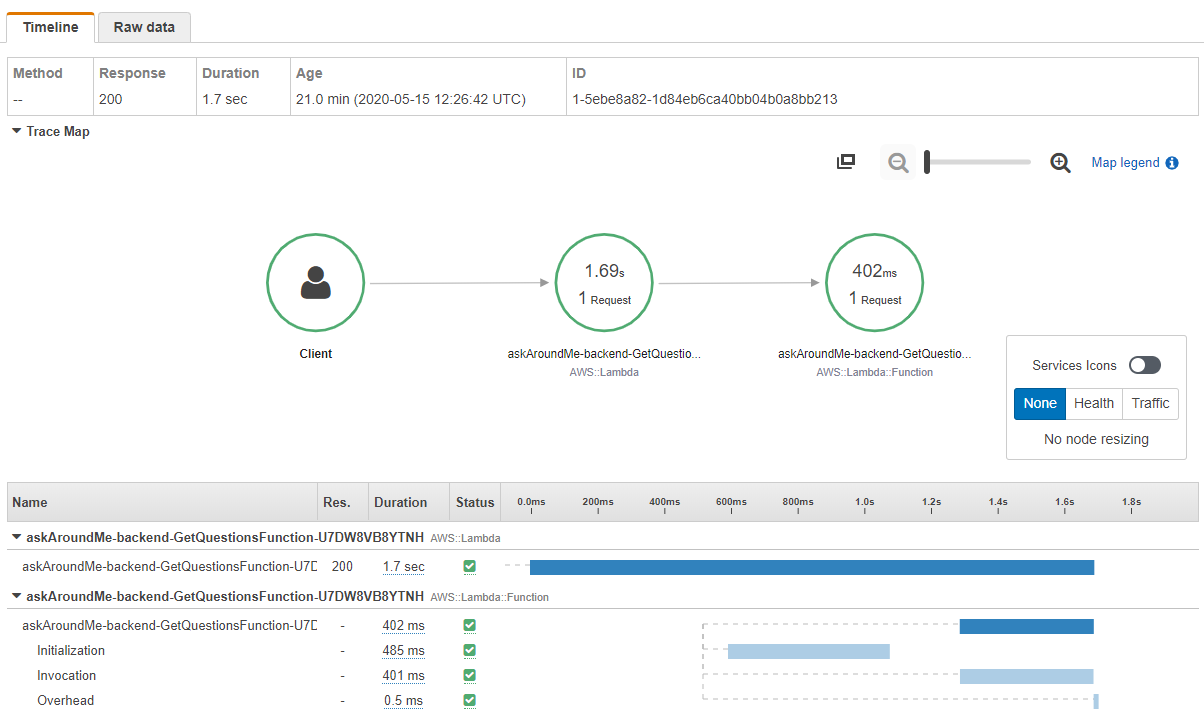
This analysis shows that this function’s performance is impacted by cold starts. The initialization of the execution environment and the function code is contributing over 1 second of latency in this example. Each of the 34 slowest invocations corresponds with scaling up events for this function.
Configuring Provisioned Concurrency for a Lambda function
Provisioned concurrency is a Lambda feature that allows you to prepare execution environments before receiving traffic. In addition to downloading the function’s code, it also runs the initialization code outside of the main Lambda handler. This provides a reliable way to keep functions ready to respond within double-digit millisecond latency.
While all Provisioned Concurrency functions start more quickly than the existing on-demand Lambda execution style, this is particularly beneficial for certain function profiles. Runtimes like C# and Java have much slower initialization times than Node.js or Python, but faster execution times once initialized. With Provisioned Concurrency turned on, these runtimes benefit from both the consistent low latency of the function’s start-up and the performance during execution.
To enable Provisioned Concurrency for a Lambda function:
- Go to the AWS Lambda console and then choose your existing Lambda function.
- Provisioned concurrency settings must be applied to a published version or an alias. Go to the Actions drop-down and choose Publish new version.

- Choose Publish. Scroll down to the Concurrency panel and choose Add Configuration.

- Enter your preferred concurrency and choose Save.
- After a few minutes, Lambda has prepared the execution environments and the Status shows Ready in the console.

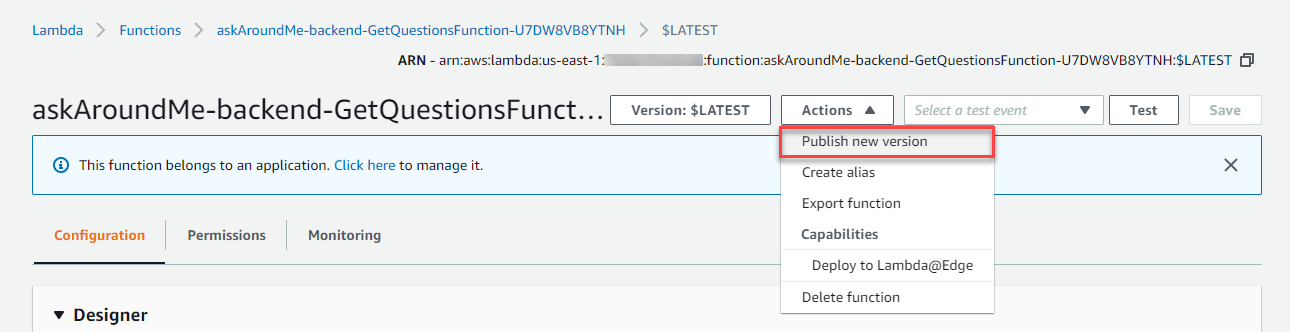
It’s important to remember that the feature is applied explicitly to a function version or alias. Ensure that your invocation method is calling this alias, and not the $LATEST version. Provisioned Concurrency cannot be applied to the $LATEST version.
When configuring Provisioned Concurrency, you select capacity to reserve. During usage, if you exceed this level, any additional functional invocations then use the on-demand model. These invocations exhibit a more typical Lambda start-up performance profile, but you are not throttled or limited from running invocations at high levels of throughput.
Using Amazon CloudWatch Logs or the Monitoring tab for your function in the Lambda console, you can see metrics for the number of Provisioned Concurrency invocations, compared with the total. This can help identify when total load is above the amount of concurrency, and you can make changes accordingly.
You can also use Application Auto Scaling to help you automate provisioning the appropriate capacity. Instead of reserving a fixed amount of capacity, this increases the amount of concurrency during peak loads, and decreases as load reduces. You can configure this in both the AWS CLI and AWS Serverless Application Model.
Comparing performance before and after Provisioned Concurrency
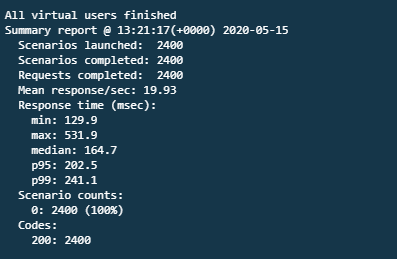
I run the same load test on the same function, now using Provisioned Concurrency – 20 requests per second over 2 minutes. The results show a median latency of 165 ms, a p95 time of 202 ms, and a slowest execution of 532 ms:
In X-Ray, the latest Response time distribution graph shows the significantly improved performance across the 2400 requests:
By enabling Provisioned Concurrency for this Lambda function, the slowest performance has been improved by 75%. The function can serve 1200 requests per minute with a much more consistent performance for users.
Function warmers and Provisioned Concurrency
The broader serverless community offers open source libraries to “warm“ Lambda functions via a pinging mechanism. This approach uses Amazon CloudWatch Events to invoke the function every minute to help keep the execution environment active. As a result, this can increase the likelihood of using a warm environment when you invoke the function.
However, this is not a guaranteed way to reduce cold starts. It does not help in production environments when functions scale up to meet traffic. It also does not work if the Lambda service runs your function in another Availability Zone as part of normal load balancing operations. Additionally, the Lambda service reaps execution environments regularly to keep these fresh, so it’s possible to invoke a function in between pings. In all of these cases, you experience cold starts despite using a warming library.
This approach might be adequate for development and test environments, or low-traffic or low-priority workloads. However, if you need predictable function start times for your workload, Provisioned Concurrency is the recommend solution to ensure predictable latency. It keeps your functions initialized and hyper-ready to respond in double-digit milliseconds at the scale you need.
Conclusion
This post examines how cold starts impact performance in serverless backends for web applications. It shows how the most important focus area is usually synchronous APIs called by the frontend application. I explain options available for targeting cold starts in the Lambda service.
Using the Ask Around Me application, I apply Provisioned Concurrency to the most latency-sensitive Lambda function. I compare the load testing performance before and after enabling this feature. This shows predictable start-up times and a 75% reduction in the slowest execution time. Finally, I show when you might use function warmers, and how Provisioned Concurrency is more suitable for latency-sensitive and production workloads.
To learn about the cost of using this feature, visit the Lambda pricing page.