Amazon Web Services Feed
Modeling business logic flows in serverless applications

Serverless applications can help you develop more agile applications that can scale automatically. By using serverless services in your architecture, this reduces the amount of boilerplate code. It also helps offload complex tasks to specialized services. As a result, a well-designed serverless application can be modified easily to deliver new feature requests, while maintaining high availability for existing production users.
Serverless applications often combine serverless services, using AWS Lambda to integrate those services and transform data. This blog post shows how to model business logic in serverless architectures, combining the services available. I also discuss how to handle state across invocations, and manage complex workflows.
Developing architecture around evolving features
Many modern applications evolve quickly to reflect the needs of their users. Developers iterate on features, releasing new versions daily or weekly, and the feature set is guided by feedback. This user-centric approach can make early architectural plans hard to develop, since developers have limited knowledge about future requirements.
Well-designed serverless applications are inherently flexible, making it faster to add new functionality as user requirements change. This is because individual parts of the workflow are specialized and loosely coupled. This can help support iterative development and also help reduce the amount of rewritten code when the design changes.
In the following example, I show how a serverless architecture can evolve due to changing requirements. In this scenario, a custom serverless application processes customer reviews in an e-commerce website.
Storing customer reviews
The serverless application saves customers reviews submitted from a webpage. The initial design of the architecture only commits the review to a database.
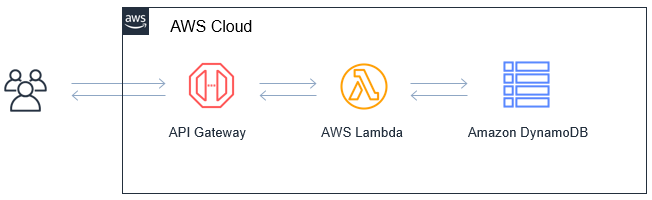
The user submits the review on the webpage, which calls Amazon API Gateway. This API invokes a Lambda function to store the review in an Amazon DynamoDB table.
Version 1: Translating reviews to a common language
After gathering feedback, there is a new requirement. Incoming reviews are currently submitted in multiple languages. These must be converted in a single language to help customer support teams.

To solve this problem, the developer adds a new Lambda function invoked from a DynamoDB stream, using Amazon Translate to process the translation work. It stores the result back in DynamoDB.
Version 2: Responding to negative reviews
Customer support needs assistance in identifying negative reviews more quickly. In this version, the application analyzes the sentiment of the review. Comments that score negatively are emailed to a manager to take further action.
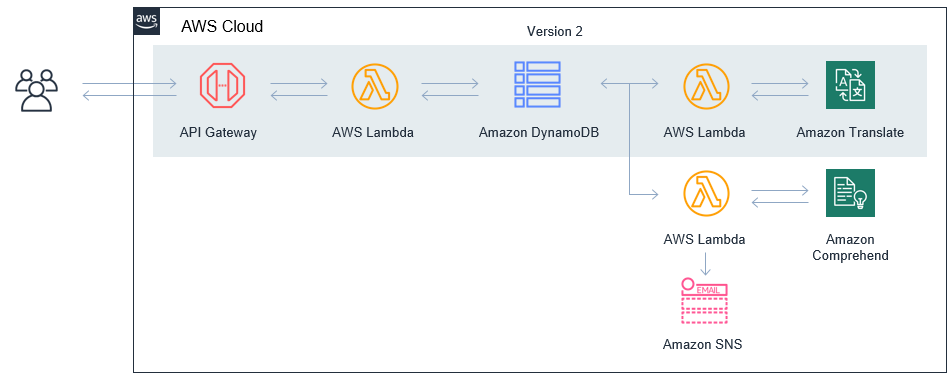
The developer adds a second Lambda function, invoked by the same DynamoDB stream. This sends the comment text to Amazon Comprehend to run a sentiment analysis. If the resulting score is under a threshold, the function uses Amazon SNS to email a manager.
Version 3: Enabling users to upload photos with the reviews
In addition to text comments, users need to upload photos. To support this feature, there is a new API Gateway endpoint that invokes a Lambda function for an Amazon S3 presigned URL. The browser uploads the media object directly to the S3 bucket.

By the latest version, the application is considerably different from the original, but the developer has been able to keep pace with new customer requests. As users create more requirements in each iteration, this serverless architecture evolves.
By using services effectively, the developer is able to assemble serverless building blocks to complete tasks quickly. By creating specialized units of custom code, additional code is added to create new features without needing to change existing code from previous versions. This makes it faster to test and deploy new functionality.
Managing local state in a stateless environment
In serverless applications, Lambda functions are ephemeral and should be designed to operate without storing state. This means that each time a function is invoked, it has no knowledge of previous interactions. Each request is handled independently.
Yet there are many tasks in an application that rely on existing state. For example, in an e-commerce application, a user may add items to a shopping cart. In a traditional web server environment, a load balancer may use sticky sessions. This setting ensure that a single user’s requests are routed to the same server. The state of the cart is kept in memory on that web server and the process is stateful.
Since Lambda functions can scale up automatically and can run in multiple Availability Zones, each invocation may happen in a different execution environment. There is no guarantee that subsequent invocations are served by the same instance of a function. By using a stateless approach, your application is indifferent if this happens, and there is no conceptual equivalent of sticky sessions.
For single Lambda functions that need to retain state, the function should fetch the state each time the function is invoked. In the e-commerce example, if a Lambda function adds an item to a shopping cart, it can fetch relevant state information from a DynamoDB table before adding the item.
Due to the low latency performance of DynamoDB, this step adds minimal overhead but means that the application has significantly better scaling capability. This can also make it easier to unit test and debug, because there is less variability caused by locally caching between invocations.
Orchestrating stateful workflows in a serverless environment
Beyond managing the state of shopping carts, it’s common for business applications to model complex workflows reflecting a custom business process. These workflows may persist for long periods of time, require human intervention, or call out to third-party systems.
For example, when a customer places an order in an e-commerce application, this triggers a workflow. There are many different potential steps and paths involved across different systems. From processing a payment to scheduling a delivery, managing the lifecycle of an order is a complex task. This gets even more difficult when you consider error states such a failed payment or a rescheduled delivery.
It’s possible to write custom code to orchestrate these flows, using a database to save the state of each process. Your code must manage retries for downstream failures and undo previous steps if a process fails. While it’s possible to engineer this for your solution, it can result in significant amounts of convoluted code. It can quickly become fragile and be difficult modify as processes change.
AWS Step Functions is designed to manage workflows, and is usually a better approach. You can model the workflow in JSON, replacing complex custom logic in your code. Step Functions can manage individual executions in a workflow that last up to one year. It can also handle different versions of workflows, making it easier to change processes without impacting in-flight executions.
Moving workflow logic into Step Functions can help create more resilient applications. You can explicitly define parallel processes, error handing, and retry logic. The service scales to handle almost any volume of individual executions, letting you focus on the custom logic specific to your application.
Workflows across different systems and beyond AWS
It’s common to build applications that need to interact with other existing applications within your organization. Increasingly, customers also use software as a service (SaaS) providers for significant parts of their systems. In traditional approaches, interoperability with these systems can be complicated.
Amazon EventBridge is a serverless event bus service designed to make it easier to communicate across systems. It integrates with third-party SaaS providers like Auth0, PagerDuty and Datadog. It also receives and routes events from AWS services and your own custom applications.
In a traditional architecture, you typically use a polling mechanism or develop a webhook to retrieve data from a third-party service. This API is publicly accessible and must be secured. You must also scale the API if the third-party service increases the volume of data sent to your endpoint.
Using an EventBridge integration, this data arrives directly in your AWS account as an event. You configure rules in EventBridge to define targets where events are routed to. The data from the third party does not use the public internet and the delivery, security, and error handling is managed by the service.
Conclusion
Serverless applications are distributed applications, using a combination of managed services and custom code. Understanding how to assemble and use these services can help improve agility and your team’s ability to deliver software feature quickly.
Writing less code and creating more specialized functions also helping layer additional features and functionality in subsequent versions. It can improve testing, reduce rewritten code, and help reduce deployment complexity.
While serverless application should be stateless at the function level, you can use DynamoDB to managing state local. This offers low latency, durable state management while enabling your functions to scale.
For managing workflows, AWS provides a number of services for building and managing workflows. EventBridge enables you to connect data between different applications and from SaaS providers. Step Functions makes it faster to develop and orchestrate complex workflows that make your application resilient.
Using these services effectively can reduce custom code and help you deliver solutions more quickly. To see this working in a sample serverless project, see the Ask Around Me blog series.